Auto-ML with Auto-Keras
In machine learning classification, we have data and labels. We try to train a machine learning model which can classify unseen data into their correct labels. Traditionally we had to perform a feature engineering process. This means we had to find a set of features which is calculated with input data that goes into a machine learning model. But with the advancement of deep learning, this burden was lifted from the user because a deep neural network could identify the features by itself.
When building a DNN, we need to find the optimum set of hyper parameters. This is called hyper parameter tuning. As an example, for CNN, the number of layers, number of kernels in each CNN layer, stride, number of dense layers, batch size used while training should be chosen so as to maximize performance. This is a very daunting task and takes a long time and experience to get it correct.
What is AutoML ?
The field of autoML aims to automate the process of hyperparameter tuning. There are systems like SMAC, TPOT, Auto-WEKA and Auto-Sklearn which can perform this task for various machine learning algorithms (for example SVM, random forest). Systems like Auto-Sklearn can even find the optimum machine learning algorithm for a given dataset. This means you input the data and it outputs a machine learning model which can classify the data best (hopefully). But none of these systems cannot tune a DNN. One of the most famous platforms which can do that are Auto-keras and Google Cloud AutoML. But google’s solution is complicated to use and may be there are security concerns due to cloud usage. This post is mainly inspired by the content in the paper “Auto-Keras: An Efficient Neural Architecture Search System” by Haifeng Jin, Qingquan Song, Xia Hu.
Neural Architecture Search (NAS)
This means searching through a set of many neural networks (possible differing in architecture) for some desirable quality. This quality is often performance. So we can use NAS techniques to iterate through many NNs till we get the right one. Researchers have used methods influenced by deep reinforcement learning, gradient based methods and evolutionary algorithms. These algorithms need to iterate through a large number of NNs to find a good solution. These methods are slow because at each step they have to re-train the NN.
Network morphism
This means changing the architecture of a NN so that its performance is not significantly affected. To explain, if we have a NN which gives accuracy of x% on a certain dataset, after we morph the network (e.g. adding/removing layers) it should still give similar results. We can incorporate network morphism to NAS. Imagine we train and evaluate a new NN while performing NAS. For the next step, we need to select another NN architecture. We define this new NN architecture by morphing the previous one and we keep the trained weights. Then when we train the new NN, we only need to train it few epochs. This significantly reduces the time needed. This could also be seen as a form of transfer learning. Even network morphism-based NAS is better than previous methods, it still needs too many training samples and is not efficient in exploring the large search space.
Search space as a tree structure
We can define each node of the tree structure as a separate NN. If we perform network morphing on a certain node, the new morphed NN becomes the earlier NN’s child. The autoML task is to navigate this tree (while creating it) and find the best performing model as soon as possible.
Bayesian optimization to find the best node
Bayesian optimization is known to perform well when we need to optimize black box functions. This can be used at each node (a NN) to find the best child of this NN (best performing NN on validation data). After we find this NN we can use network morphing techniques to create this new child NN. But existing Bayesian optimization techniques are developed to work on Euclidean space. But for this case we need to optimize going through a tree structure. So the paper changes Baysian optimization to deal with this.
Problem statement
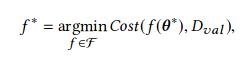
Here D_val is the evaluation set. We try to find the NN architecture which minimizes the cost (cost can be the summation of loss over all samples in evaluation set). F is the search space which contains all the candidate NNs. ϴ are the parameters of the NN.
For each NN architecture f, we find the best set of parameters. While training on the train set D_train as shown in the equation below.
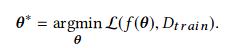
Network morphism guided by Bayesian optimization
Traditional Bayesian optimization goes through 3 steps. They are update, generation and observation. Update : train the underlying gaussian process model with existing architectures and their performance Generation : generate the next architecture Observation : obtain the performance of the newly generated architecture by training it and evaluating on data This process is adapted to solve network morphism-based NAS
Edit distance between two NNs
Since existing Bayesian optimization techniques demand Euclidean space, we have to convert the tree structure into something that uses Euclidean space. This can be achieved if we can quantify the difference between each node in the tree. This is defined as the edit distance and symbolized by d(fa,fb) where fa and fb are two NNs. Refer the paper on how to define this. If we can obtain fb from fa with only few morphs, d(fa,fb) is less. On the other hand if we need to perform many morphine operations, this means d(fa,fb) is large.
Operation of Auto-kears
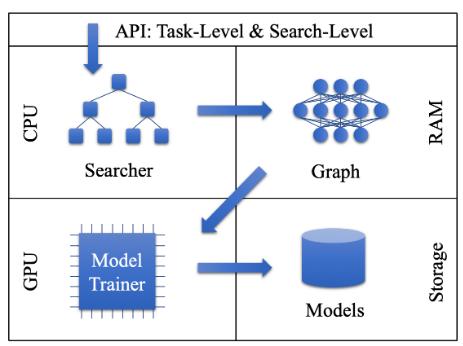
When the user starts auto-ML the process starts in CPU and searches the tree. Bayesian optimizer is running here. After the process finds the next node, the graph is created in the RAM with network morphing techniques. A NN is represented as a graph for ease of operation. Afterwards, the model is trained and tests on GPU. Selected models are stored in the storage. Then the process goes back to searcher. This continues until terminated.
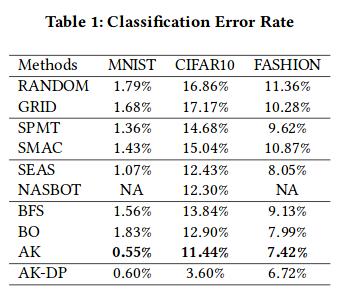
From the following table it can be seen that auto keras (AK) performs better than other methods.
Testing autokeras library
I tested autokeras by trying to build a classifier which can classify vocal emotions from Berlib Emodb dataset. Then I compared this CNN model with a hand tuned one. It was a Modified CNN taken from paper “Evaluating deep learning architectures for Speech Emotion Recognition” by Fayek et.al.
Results
Validation accuracy of the CNN model modified from the paper :
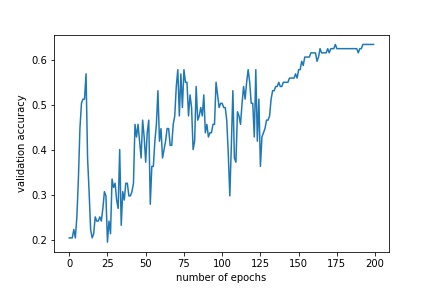
Of the best CNN model found from autokeras:
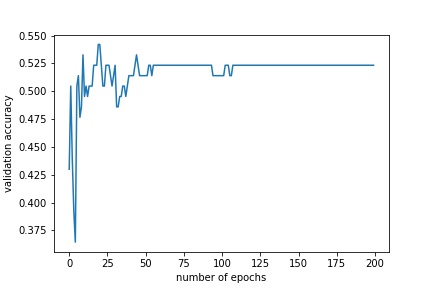
It can be seen that the manually generated and tuned CNN from the paper still performs better than the one found by autokeras.