Classifying Emotions with Neural Networks
This articles provides how to implement a neural network based classifier to classify emotions from voice data. To explain, if some one is speaking through a microphone, a machine learning agent can listen to that speech and try to determine the emotional state of the person. Here, emotional state could mean various types of emotions such as happy, sad, surprise, anger…etc. The motivation for such a system could be numerous. One example would be a mobile robot roaming in a house and interacting with people. While hearing these people’s voice and/or looking at their faces, this agent can try to determine the emotional state the person is at and then take actions according to that state. If the person is feeling sad, for example, the robot can choose to play a happy song to make the person feel better.
Dataset
Data sets provide labeled data to test various machine learning algorithms. These data sets may contain different people speaking in front of a microphone and/or camera while showing various kind of emotions. These voice clips/videos are labelled. that means the people who collected these data have provided us with the information stating if this particular voice clip shows which emotion. One such data set is RML dataset (which can be found at https://github.com/emotion-database/RML_Emotion_Database). It has various people speaking with various emotions. The emotions contained are Anger, Disgust, Fear, Happiness, Sadness and Surprise. I extracted just voice from these clips and try to classify them into different emotions with deep neural networks.
Extracting Features
To classify emotion with audio data, we need to extract features. To do this, I first extracted audio as .wav files from the videos in RML data set.
Adding Noise
Adding noise to training data is a useful technique to generalize the classification model. To achieve this I use a noise file (a file that contain some noise from traffic audio clip) and mix this with the actual emotion audio clips.
Then I calculate audio features with open smile. For details on how to use OpenSMILE visit https://www.audeering.com/opensmile/
Then I built a deep neural network with Keras deep learning library for python. Code can be found in by github repo : https://github.com/sleekEagle/audio_emotion_classification
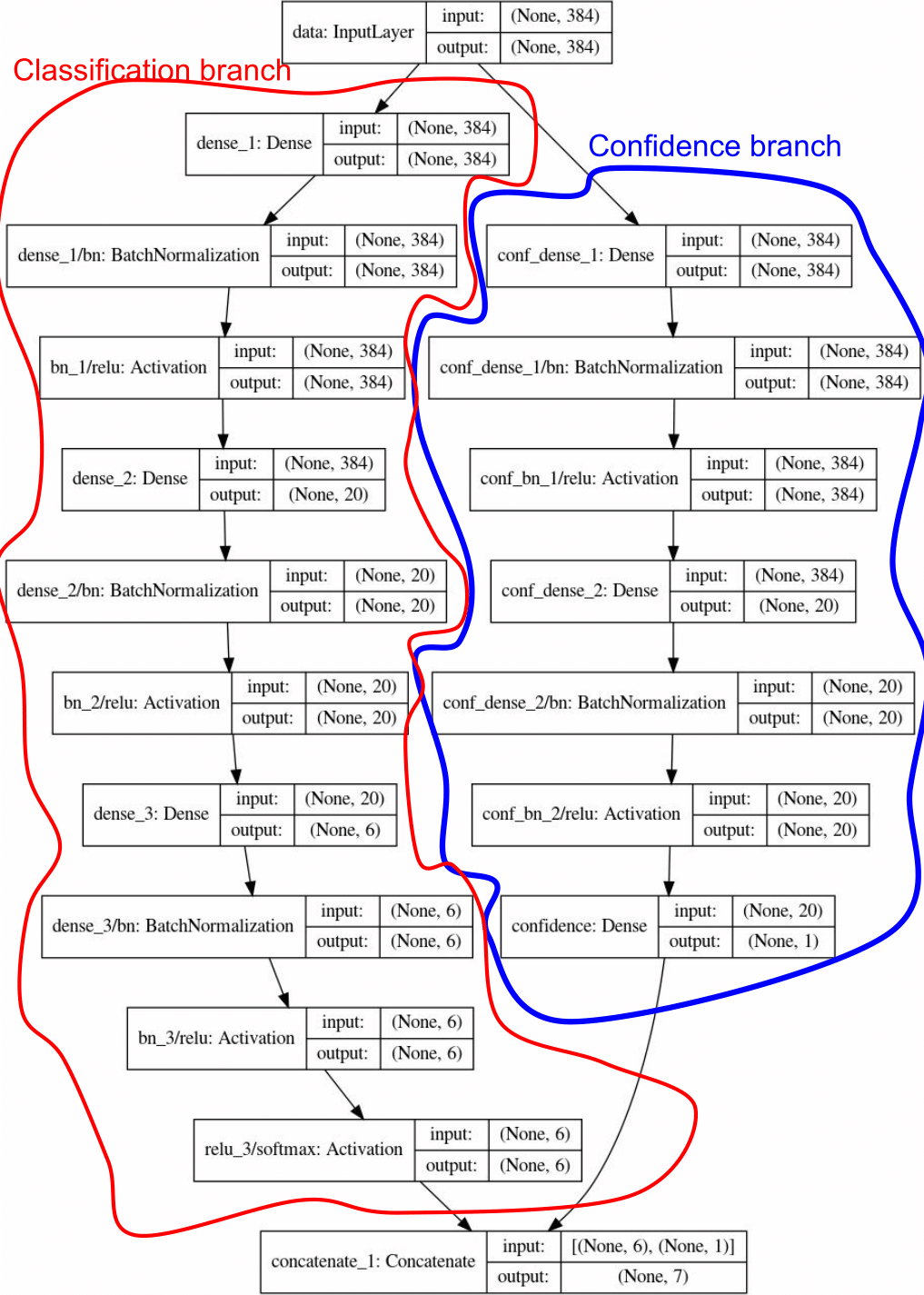
This network uses a confidence prediction branch to predict the confidence of its own predictions. To know more details check out my article on neural networks with confidence estimation.
The network Structure
Results
The training set (audio clips extracted from RML dataset) were divided into training, testing and validation sets. The model was traind on the training set and validated on the validation set. The results are as follows for each emotion class.
| Class | Accuracy |
|---|---|
| angry | 0.79 |
| disgust | 0.83 |
| fear | 0.17 |
| happy | 0.42 |
| sad | 0.61 |
| surprise | 0.90 |